Index-TTS
综合介绍
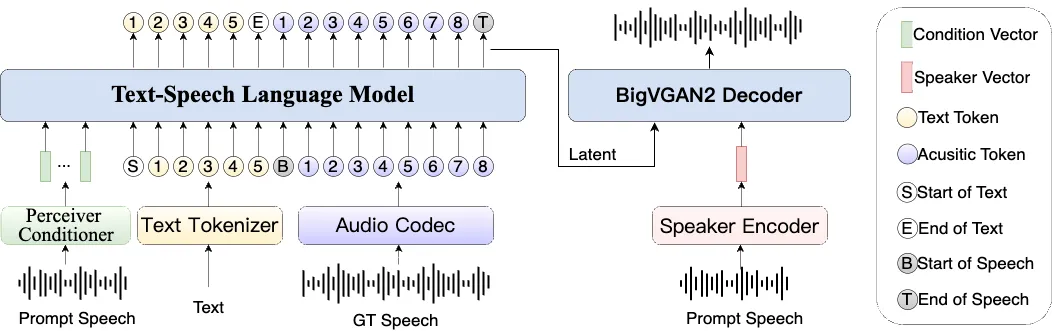
Index-TTS 是一个开源的、工业级可用的文本转语音(TTS)系统。它基于 GPT 风格的架构,并融合了 XTTS 和 Tortoise 等先进模型的设计思路。该项目的主要特点是实现了“零样本(Zero-Shot)”声音克隆,这意味着用户只需提供一个简短的参考音频(例如5-10秒),系统就能模仿该音频的音色来朗读任意文本,而无需为这个新音色重新训练模型。Index-TTS 对中文场景进行了特别优化,它采用字音混合建模方法,可以利用拼音快速修正汉字的错误发音,还能通过标点符号控制语音的停顿,让生成的声音更加自然。为了提升音质和音色相似度,系统集成了 BigVGAN2 声码器。从项目的联系方式和贡献者信息来看,该项目与B站(bilibili)有紧密关联,旨在提供一个高效且可控的语音合成方案。
功能列表
- 零样本声音克隆:仅需一段短音频作为参考,即可克隆该音色来合成任何文本的语音。
- 高音质合成:集成 BigVGAN2 声码器,优化了音频输出质量,声音清晰且真实。
- 发音和停顿控制:在中文场景下,支持使用拼音修正多音字或生僻字的发音;能识别标点符号,并在对应位置产生自然的停顿。
- 跨语言支持:在评测中表现出优秀的中文和英文合成能力。
- 高效率与稳定性:改进了说话人条件特征表示,并引入 conformer 条件编码器,提升了训练稳定性和推理效率。
- 多种使用方式:提供简单的命令行工具、直观的Web用户界面(WebUI)和可集成的Python代码库,满足不同开发者的需求。
- 模型开源:模型参数和推理代码均已开源,方便社区研究和使用。
使用帮助
Index-TTS 提供了详细的安装和使用流程,让用户可以快速在自己的电脑上部署和体验。下面是完整的操作步骤。
第一步:环境设置
首先,你需要一个干净的Python环境。官方推荐使用 conda 来管理环境,这样可以有效避免不同项目之间的依赖冲突。
- 克隆项目代码打开你的终端(命令行工具),将Index-TTS的官方代码库下载到本地。
git clone https://github.com/index-tts/index-tts.git - 创建并激活Conda环境我们为Index-TTS创建一个独立的Python 3.10环境。
conda create -n index-tts python=3.10 conda activate index-tts执行后,你的终端提示符前面会出现
(index-tts)字样,表示已进入该环境。 - 安装FFmpegFFmpeg是一个处理音视频的必要工具。
# 在Linux上可以使用apt # apt-get install ffmpeg # 推荐使用conda安装,兼容性更好 conda install -c conda-forge ffmpeg - 安装PyTorchPyTorch是驱动AI模型的核心框架。请根据你的电脑是否有NVIDIA显卡选择合适的版本。以下命令安装的是支持CUDA 11.8的版本。
pip install torch torchaudio --index-url https://download.pytorch.org/whl/cu118如果你的电脑没有NVIDIA显卡,可以安装仅使用CPU的版本,具体命令请参考PyTorch官网。
- 安装项目依赖进入刚刚克隆的项目目录,然后安装Index-TTS作为软件包。
cd index-tts pip install -e .特别注意:Windows用户在执行上一步时,可能会遇到
pynini库安装失败。如果出现ERROR: Failed building wheel for pynini的错误,请按照以下步骤手动安装:# 先用conda安装pynini conda install -c conda-forge pynini==2.1.6 # 再安装一个不含依赖的WeTextProcessing库 pip install WeTextProcessing --no-deps # 最后再执行项目安装 pip install -e .
第二步:下载模型文件
环境配置好后,还需要下载预训练好的模型文件,系统才能正常工作。模型文件存放在Hugging Face上。
在你克隆的 index-tts 目录下,新建一个名为 checkpoints 的文件夹。然后通过以下方式下载模型。
- 方式一:使用
huggingface-cli(推荐)这是官方推荐的下载工具,支持断点续传。# 如果你在中国大陆,下载速度慢,可以先设置镜像 export HF_ENDPOINT="https://hf-mirror.com" # 下载IndexTTS-1.5模型到checkpoints目录 huggingface-cli download IndexTeam/IndexTTS-1.5 \ config.yaml bigvgan_discriminator.pth bigvgan_generator.pth bpe.model dvae.pth gpt.pth unigram_12000.vocab \ --local-dir checkpoints - 方式二:使用
wget逐个下载如果你的网络环境没有问题,也可以用wget命令将文件逐个下载到checkpoints目录。wget https://huggingface.co/IndexTeam/IndexTTS-1.5/resolve/main/config.yaml -P checkpoints wget https://huggingface.co/IndexTeam/IndexTTS-1.5/resolve/main/bigvgan_generator.pth -P checkpoints # ...(依次下载所有其他模型文件)
第三步:开始使用Index-TTS
Index-TTS提供了三种灵活的使用方式,你可以根据自己的偏好选择。
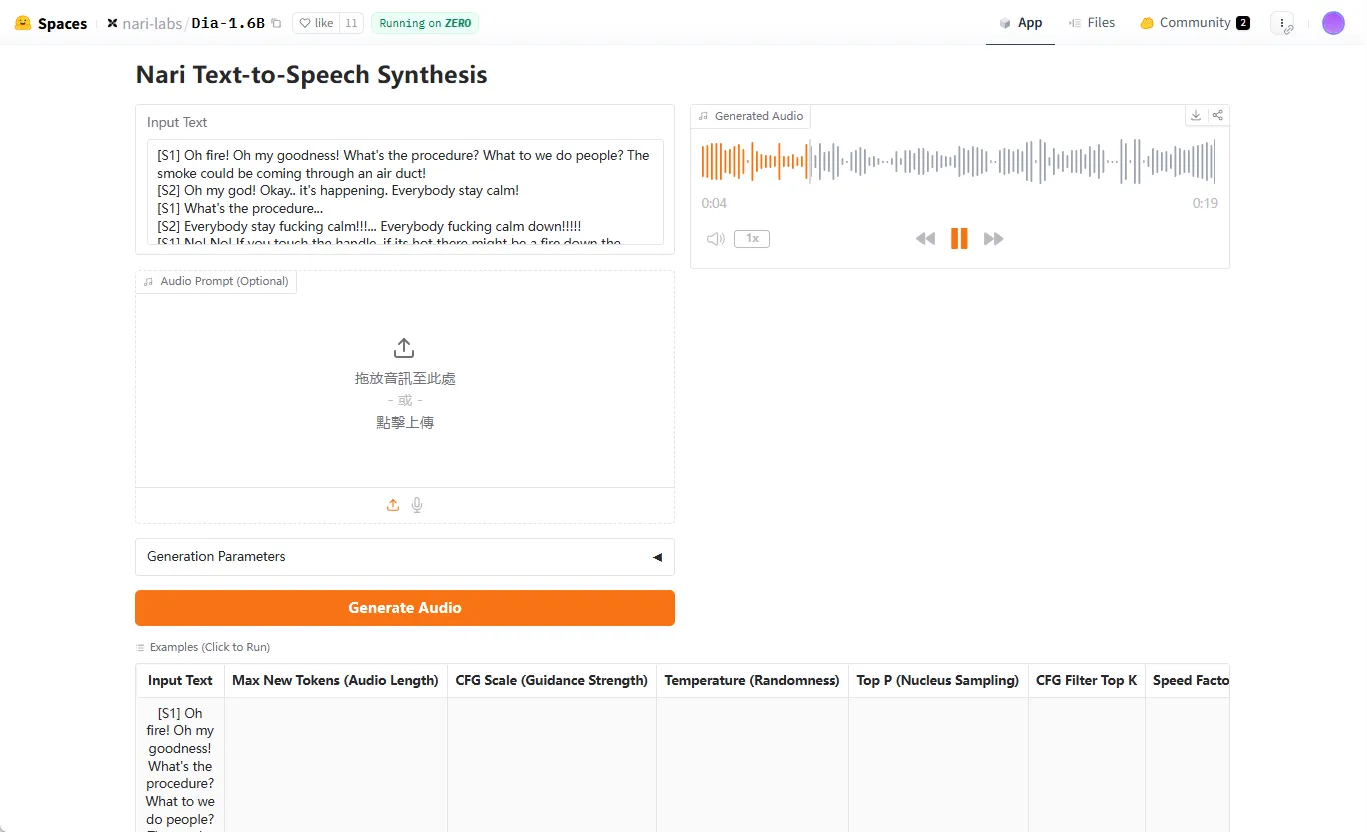
- 使用Web用户界面(WebUI)这是最直观、最适合普通用户的方式。
- 安装WebUI依赖
pip install -e ".[webui]" --no-build-isolation - 启动Web服务在
index-tts根目录下运行:python webui.py - 访问界面启动成功后,终端会显示一个本地网址,默认为
http://127.0.0.1:7860。在浏览器中打开这个地址,你就能看到操作界面。你可以在界面上上传一段参考音频(reference_voice.wav),输入要转换的文本,然后点击生成,即可听到克隆后的声音。
- 安装WebUI依赖
- 使用命令行工具对于开发者或喜欢自动化流程的用户,命令行工具非常方便。
- 命令格式
indextts "你要转换的文本内容" --voice "参考音频.wav" --output "输出文件名.wav" - 示例假设你有一段名为
my_voice.wav的音频,想用它的音色说一句话,可以这样操作:indextts "大家好,欢迎体验Index-TTS,这是一个神奇的声音克隆工具。" \ --voice my_voice.wav \ --model_dir checkpoints \ --config checkpoints/config.yaml \ --output generated_speech.wav命令执行完毕后,会在当前目录下生成一个名为
generated_speech.wav的音频文件。你可以使用--help查看更多高级选项。indextts --help
- 命令格式
- 在Python代码中集成如果你想将Index-TTS的功能集成到自己的应用程序中,可以直接调用它的Python类。
- 示例代码创建一个Python文件(例如
test.py),输入以下内容:from indextts.infer import IndexTTS # 1. 初始化模型,指定模型目录和配置文件 tts = IndexTTS(model_dir="checkpoints", cfg_path="checkpoints/config.yaml") # 2. 指定参考声音文件和要合成的文本 voice_path = "path/to/your/reference_voice.wav" # 替换成你的参考音频路径 text_to_speak = "只需一段简短的音频,AI就能模仿我的声音。这项技术将改变内容创作的方式。" output_file_path = "final_output.wav" # 指定输出文件名 # 3. 执行推理并保存结果 tts.infer(voice_path, text_to_speak, output_file_path) print(f"语音已生成,保存为 {output_file_path}")
运行这个Python脚本,即可在指定路径找到生成的音频文件。
- 示例代码创建一个Python文件(例如
应用场景
- 内容创作视频博主、播客主播或有声书制作者可以克隆自己的声音。这样一来,只需提供文稿,即可自动生成配音,大大提升了内容生产效率,也方便修正口误,无需重新录制整段音频。
- 个性化AI助手用户可以为自己的智能音箱、手机助手或个人应用录制一段自己的声音或家人的声音。通过Index-TTS,可以生成一个带有亲切感的、独一无二的语音助手,让交互体验更加温暖。
- 教育与培训制作在线课程时,讲师可以克隆自己的声音,快速为PPT或教学视频生成旁白。当课程内容更新时,也只需修改文本即可重新生成配音,无需本人再次录制。
- 游戏开发游戏开发者可以使用该工具为游戏中的大量非玩家角色(NPC)生成对话。只需少数几位配音演员提供参考音频,就能衍生出大量不同但风格一致的NPC声音,降低了配音成本。
QA
- 什么是“零样本(Zero-Shot)”声音克隆?“零样本”或“零次学习”指的是AI模型在未经过特定训练的情况下,能够直接完成一项新任务。在Index-TTS中,这意味着你不需要为了模仿某个人的声音而专门去训练一个新模型。你只需提供一个这个人的简短音频样本(比如5-10秒),模型就能立即分析其音色、韵律和音调等特征,并用这些特征去朗读你提供的任何新文本。
- 使用Index-TTS需要很强的电脑配置吗?对于推理(即生成语音),拥有一块NVIDIA的GPU会大大加快生成速度,这也是官方推荐的配置。但是,模型也支持仅在CPU上运行,只是生成音频所需的时间会更长。如果你只是偶尔使用或生成较短的音频,CPU也是可以接受的。对于安装和运行,建议至少有16GB的内存。
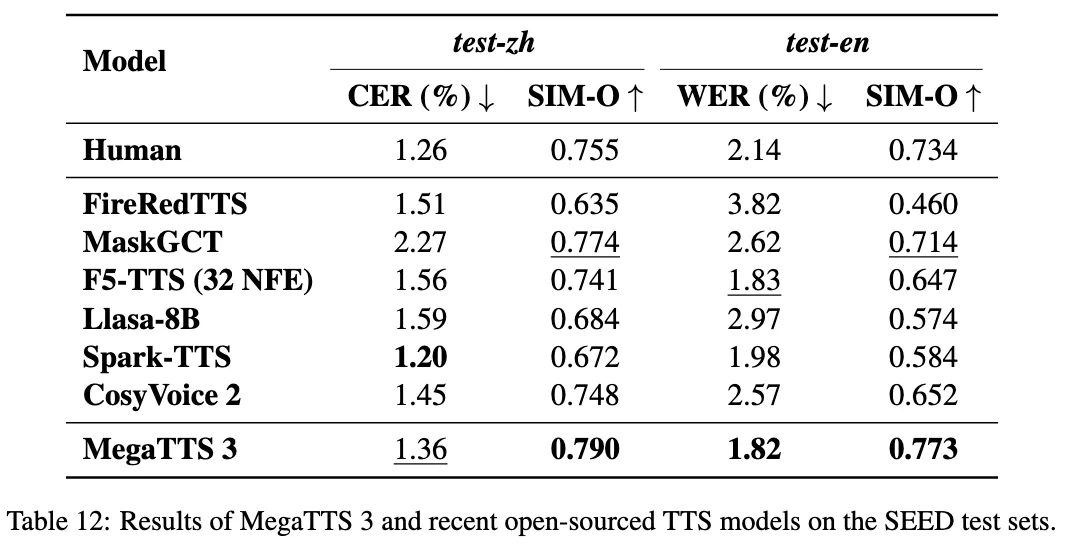
- Index-TTS主要支持哪些语言?根据官方发布的评测数据,Index-TTS在中文和英文上都表现出了非常高的性能,生成的语音在清晰度(词错误率低)和音色相似度上都达到了顶尖水平。因此,它是一个优秀的跨语言语音合成工具,尤其擅长处理中英文混合的文本。
- 这个项目和B站(bilibili)有什么关系?从项目留下的联系邮箱(
@bilibili.com)和贡献者信息来看,Index-TTS很可能是由B站内部的团队或与B站有深度合作的开发者主导和维护的。项目的目标是打造一个“工业级”系统,也暗示了其应用场景可能包括B站的视频创作工具、虚拟主播等业务。